検索順位チェックツールの比較と、無料で使えるSEOツール(検索順位チェックツール)をPythonで自作してみた話
目次
今回の記事は少し長めです。
- 前半が検索順位チェックツールの比較
- 後半が自作の検索順位チェックツールのご紹介となります。
検索順位チェックツールの比較
RankTracker
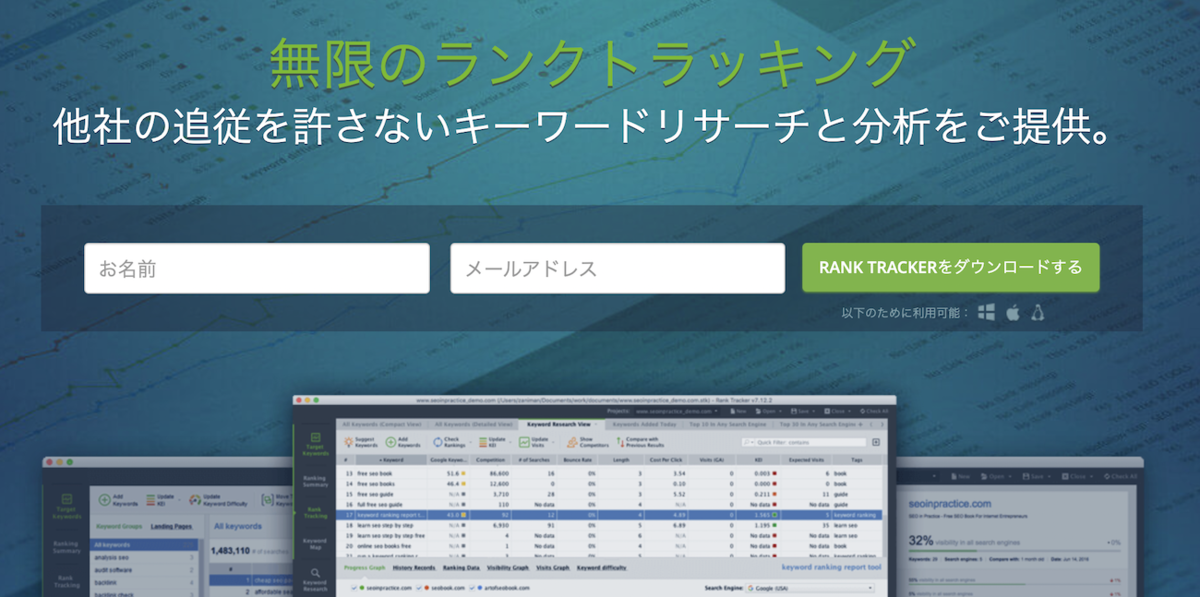
検索順位チェックツールだと有名なクライアントソフトの一つで、Mac環境でも使えるのが魅力的。
そもそも検索順位チェックツールはどのようなシーンで使われるの?
このような検索順位チェックツールはWebマーケターの方やブロガーの方などが利用しています。
基本的にはSEOの改善を行い、検索流入の向上を目指す過程で利用されます。
具体的な作業の流れとしては、
- キーワード選定 2.コンテンツ制作(リライト)
- 公開
- 検索順位のチェック(SEOに関する検証)
- 改善案を作成
- リライト(再び
2に戻る)
そしてこの工程の中の 4. 検索順位のチェック(SEOに関する検証) の作業は、ツールを使うかどうかで大幅に作業効率が異なってくる部分でもあります。
私もここで実際に検索順位チェックツールを作っていく過程で実感しましたが、検索順位チェックは手作業で行っていくと膨大に時間が溶けます。
ただ、自作のツールだと考慮することが多く、やはり実用的かと問われると首を傾けざる終えません。
(小規模に使うなら自作ツールでも問題ありませんが、膨大な量のサイトの検索順位をチェックする場合などは有料のツールを用いたほうが遥かに楽ですし、費用対効果の面でも軍配が上がります)
例えば、こちらのRankTrackerを用いることでこの検索順位チェックの工数を大幅に減らすことで、他の作業に時間と工数を割けるようになるというわけです。
RankTrackerでやれること
- 自サイトの検索順位チェック
- 競合サイトの検索順位チェック
- 競合サイトを登録しておくことで、競合サイト側の検索順位チェックも行えます
- 順位チェックの予約登録
- 順位チェック処理を動かす際の予約が行なえます。要は定時バッチ処理やcron的なことが行えるということですね。
- SEOのチェックキーワードのグループ登録
- カテゴリーごとにまとめたりできます
余談ですが、定時実行は自作のツールでもAWSのlambdaなどから実行しようと一瞬思いましたが、検索順位チェック処理には膨大な時間があるので、すぐに諦めました。毎日実行していたらAWS lambdaの無料枠を超えそうな気がして...
そういう意味でもガッツリ毎日使っていきたいなら検索順位チェックツールはRankTrackerのような有償ツールを使ったほうが良いかもしれません。
RankTrackerの利用料金
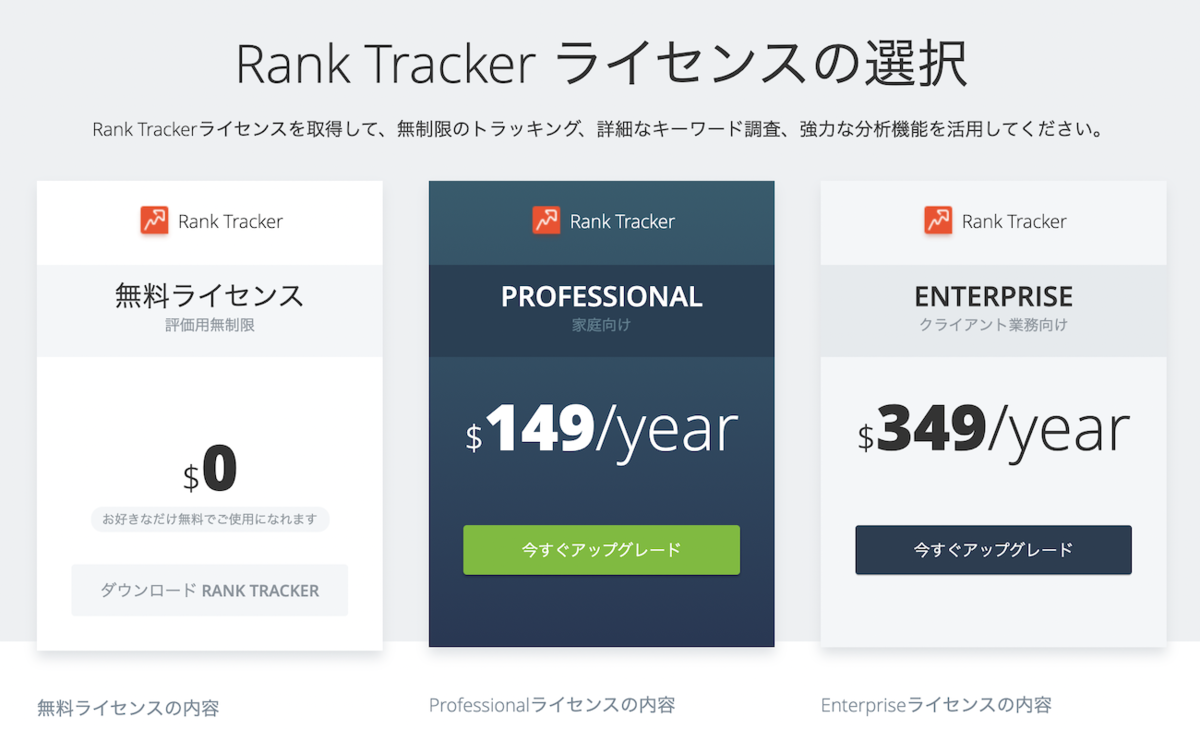
RankTrackerは無料から使えます。
ただ、無料は試用版的な立ち位置なので、実際に使うとしたら、個人利用なら年単位で $149 のProfessionalプラン、マーケターやSEOコンサルのようなクライアントワークをするような方であれば、年単位 $349 のEnterpriseプランを利用することになると思います。
ちなみにProfessionalプランで下記のような事ができるようになります。
- プロジェクト毎の競合他社 5社
- プロジェクトの保存(無制限)
- SEOタスクのスケジュール
- Captcha対策用の検索の専用クエリ処理システム
- クリップボードへのデータのコピー
- レポートの印刷(透かし入り)
詳細は上記ページにありますので、ぜひ覗いてみてください。
GRC
次はRankTrackerと双璧をなす(?)と勝手に考えている、GRC。
というか日本では、GRCを利用している方のほうが多いような印象を受けます。
GRC、RankTrackerとやれることはそれほど変わらず、料金はお安く、GRC推しの方をよく見る気がします。
GRCでやれること
GRCでやれることですが、
- サイト情報の登録をした上での検索順位チェックの実施
- 検索順位の推移をグラフ表示
- 検索順位チェックの自動実行(指定日時での自動実行)
と、RankTrackerとほぼ同様の内容となっています。
UIデザインは少し前のWindowsアプリといった趣で、決して洗練されたデザインではないですが、これはこれでいかにも玄人向けのツールと言った雰囲気が漂っていて、私は嫌いではありません(笑)
GRCの料金プラン
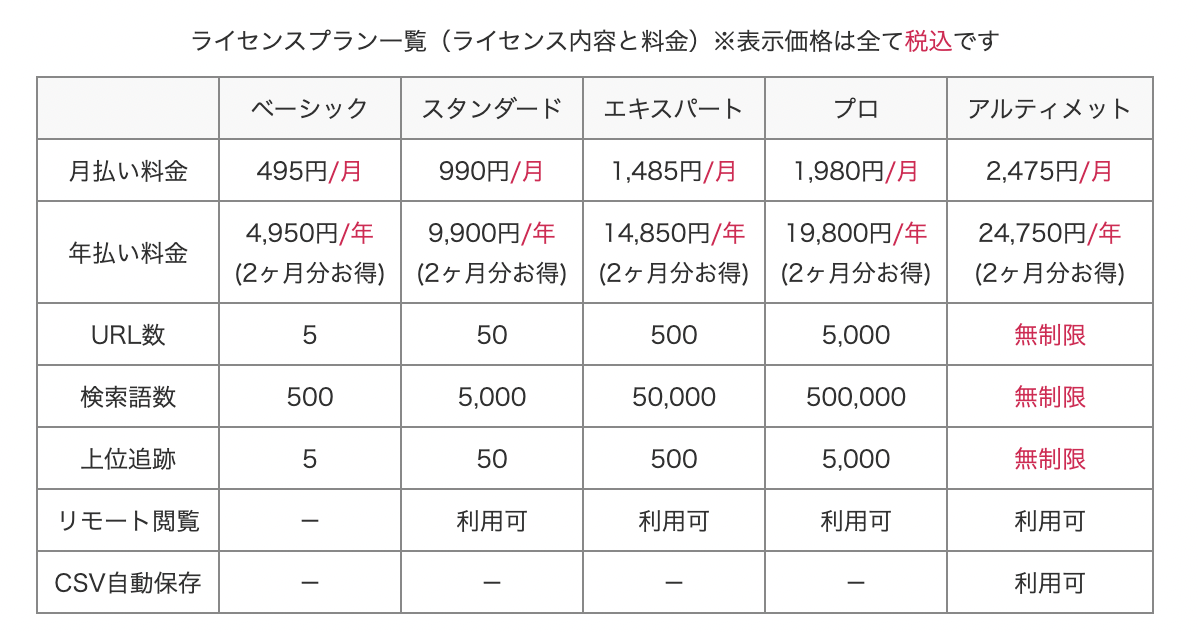
こちらがGRCの料金プランです。
内容を見ると明らかにRankTrackerよりもGRCのほうがお得です。
うーん、これはお得。と改めて見ていて思いました。
【注意!】MacユーザはGRCを利用できない
すごく良さそうなGRCですが、残念ながらMacでは使えません。
正確にはMac上に仮想環境を構築して、その上で動くWindows上でなら動くと思いますが、わざわざそこまでやるぐらいならRankTrackerを使ったほうが良いです。
(そもそもWindows使う上で、そちらのライセンス料もかかるので、結果的に費用がかかります)
GRCはMacでも使える、というブログを見かけますが、これらのブログの情報はたいてい
- 情報が古い
- 仮想環境上のWindowsでやる前提
になっているので、注意が必要です。
上記ページが公式サイトに存在しますが、このやり方は現在のMacでは実現できません。
現在のmacOSではここで説明されているWineはまともに動かなくなっているので、実現はできないと思います。
私は別の作業でこのWineについて一時期触れていましたが、結局、現状のWineではどう頑張ってもうまく動かないため挫折しました。
もしかしたらうまく動かせる方法が残されているかもしれませんが、それをやるぐらいであればMacユーザはRankTrackerをインストールして動かしていたほうがたくさんの時間を無駄にせずに済みます。
検索順位を調べるためのツールをPythonで自作してみた。
さて、ここまでRankTrackerとGRCという有名な検索順位チェックツールについて書いてきました。
このように検索順位を調べるためのツールというのは色々と出ていますが、単純に 指定したページ に対する 特定のキーワードの順位 を調べるだけならPythonなどを使って簡単に調べられそう、と不意に思い立ち、自作してみることにしました。
ちなみにこのようなツールは既に自作されている方がいましたが、Googleの検索結果画面のアップデートにより動かなくなっているものばかりでした。そして、このツールもそのうち動かなくなると思います。
もし使いたいけど動かないという場合は、動くようにメンテンナンスしようと思うのでコメントください。
また一応動作が問題ないことはこちらで確認していますが、利用は自己責任でお願いします。
なお、コード作成の際には上に書いた先人たちの処理も参考にさせてもらっています。感謝です。
ツールの動作環境と注意点
なお、このツールはGoogle検索結果の順位のみを調べるツールとなります。
現段階ではまだ試作版的な立ち位置なので、もし利用する際は下に貼ったソースコードをご自身のPC上にコピペして利用してもらうことになります。
ある程度、うまく動くようになったらGitHubとかでドキュメントつきで公開しようとか考えていますが、いずれGoogleのアップデートで動かなくなると思うので、そこの運用をどうするか次第。
利用するにはターミナル(黒い画面)からコマンドを実行する必要があります。
また、筆者の環境はmac環境であり、他の環境からテストをしておりません。
os固有の機能は使っていないと思うので、Windowsでもたぶんそのまま動くような気がしますが、動かなければコメントいただければ、動くように修正しようと思います。
検索順位チェックツールのコード
まずは下記のコードを main.py など適当なPythonスクリプトファイルにコピペしてください。
from bs4 import BeautifulSoup import requests import random import time import pandas as pd import datetime import json import logging # class selector SELECTOR = 'C8nzq' # user agent USER_AGENT = 'Mozilla/5.0 (Linux; Android 6.0.1; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Mobile Safari/537.36' def get_headers(): headers = { 'User-Agent': USER_AGENT } return headers def get_target_site_title(target_url): target_site = requests.get(target_url, headers=get_headers()) target_soup = BeautifulSoup(target_site.text, 'html.parser') title = target_soup.find('title').text return title def get_search_url(keyword): return 'https://www.google.co.jp/search?hl=ja&num=100&q=' + keyword def search_index(keyword, target_url): try: title = get_target_site_title(target_url) res = requests.get(get_search_url(keyword), headers=get_headers()) soup = BeautifulSoup(res.text, 'html.parser') urls = [a.get('href') for a in soup.findAll('a', class_=SELECTOR)] today = datetime.date.today().strftime("%Y/%m/%d") url_index = 0 for url in urls: if target_url not in url: url_index += 1 else: url_index += 1 break series = pd.Series([today, url_index, target_url, title, keyword], index=df.columns) return series except: pass if __name__ == "__main__": logging.basicConfig( level=logging.INFO, format='%(asctime)s %(levelname)-8s: %(message)s' ) logging.info("Start!") config_file = './config.json' with open(config_file, 'r') as f: json = json.load(f) urls = json['urls'] keywords = json['keywords'] df = pd.DataFrame(columns=['date', 'rank', 'url', 'title', 'keyword']) for url in urls: logging.info("Check URL: " + url) for keyword in keywords: logging.info("Check keyword: " + keyword) print("============") series = search_index(keyword, url) print(series) df = df.append(series, ignore_index = True) random_sleep_time = random.randint(70,100) print("============") logging.info("Wait...: " + str(random_sleep_time)) time.sleep(random_sleep_time) file_name = 'rank_' + str(datetime.date.today().strftime("%Y%m%d")) + '.csv' df.to_csv(file_name) logging.info("Generate csv file: " + file_name) logging.info('Finish!')
実行するためにはいくつかのライブラリをpip経由でインストールする必要があります。
インストール必要なライブラリは下記の3つです。
- beautifulsoup4
- requests
- pandas
そのため、pipコマンドを使って下記のようにインストールします。
pip install beautifulsoup4 requests pandas
自作の検索順位チェックツールを動かすまでの設定
次に実行前にチェック対象のページURLと、チェック対象のキーワードを設定する必要があります。
コピペしたPythonコードと同じディレクトリに config.json というファイルを作成して、下記のコードをコピペして、自分の調べたい内容に適宜書き換えてください。
urlsと書かれている配列の中にチェックしたいページURLを格納していきます。keywordsと書かれている配列の中に調べたいキーワードを格納していきます。- 記載された
urls内のURLに対して、keywords内のキーワードをすべてチェックしていきます。- つまり下記の場合だと、ページURLが2つに対して、keywordsが5つのため、計10回チェックをかけることになります。
{ "urls": [ "https://shinshin86.hateblo.jp/entry/2021/03/10/083147", "https://shinshin86.hateblo.jp/entry/2021/04/26/111413" ], "keywords": [ "Gatsby SEO対策", "Gatsby SEO", "サイト SEO対策", "サイト SEO", "SEO対策" ] }
ツールの実行
config.json を準備し終えたら、準備は以上です。
下記のコマンドでPythonスクリプトを実行していきます。
(ここではPythonスクリプトファイルを main.pyとしています)
python main.py
ちなみにこのスクリプトはPython3系を動かすことを前提にしています。
私の環境ではPython3系の実行は python3 コマンドが行ってくれるので、下記のコマンドでスクリプトを走らせています。
pythonコマンドだとエラーになるという方は、下記のコマンドで打ってみてください。
python3 main.py
後はひたすら待ちます。
というのも、このツールのようにプログラムからGoogle検索結果にアクセスする場合、あまりに感覚が短ったりすると、Google検索結果で画像認証(reCAPTCHA)が出るらしいので、結構な待ち時間を間に挟むようにしています。
そのため、プログラム終了までかなり時間がかかるので、ターミナルは開きっぱなしのまま、別の作業をしていたりすることをおすすめします。
なお、スクリプトを実行すると下記のようなログがターミナルに出力されます。
$ python3 main.py 2021-04-30 10:51:38,203 INFO : Start! 2021-04-30 10:51:38,208 INFO : Check URL: https://shinshin86.hateblo.jp/entry/2021/03/10/083147 2021-04-30 10:51:38,208 INFO : Check keyword: Gatsby SEO対策 ============ date 2021/04/30 rank 16 url https://shinshin86.hateblo.jp/entry/2021/03/10... title 【Gatsby の SEO対策】Gatsby + Netlifyで運用しているサイトで意図し... keyword Gatsby SEO対策 dtype: object ============ 2021-04-30 10:51:39,506 INFO : Wait...: 71 2021-04-30 10:52:50,512 INFO : Check keyword: Gatsby SEO ============ date 2021/04/30 rank 64 url https://shinshin86.hateblo.jp/entry/2021/03/10... title 【Gatsby の SEO対策】Gatsby + Netlifyで運用しているサイトで意図し... keyword Gatsby SEO dtype: object ============ 2021-04-30 10:52:51,630 INFO : Wait...: 98 2021-04-30 10:54:29,636 INFO : Check keyword: サイト SEO対策
そして、プログラムが完了すると同じディレクトリ内に日付がタイトルに入った csv ファイルが生成されます。
(rank_今日の日付.csv というファイル名で生成されます。同じ日にプログラムを2回実行してしまうと、元のファイルを上書きしてしまうので注意)
csvファイルの中身はこんな感じ
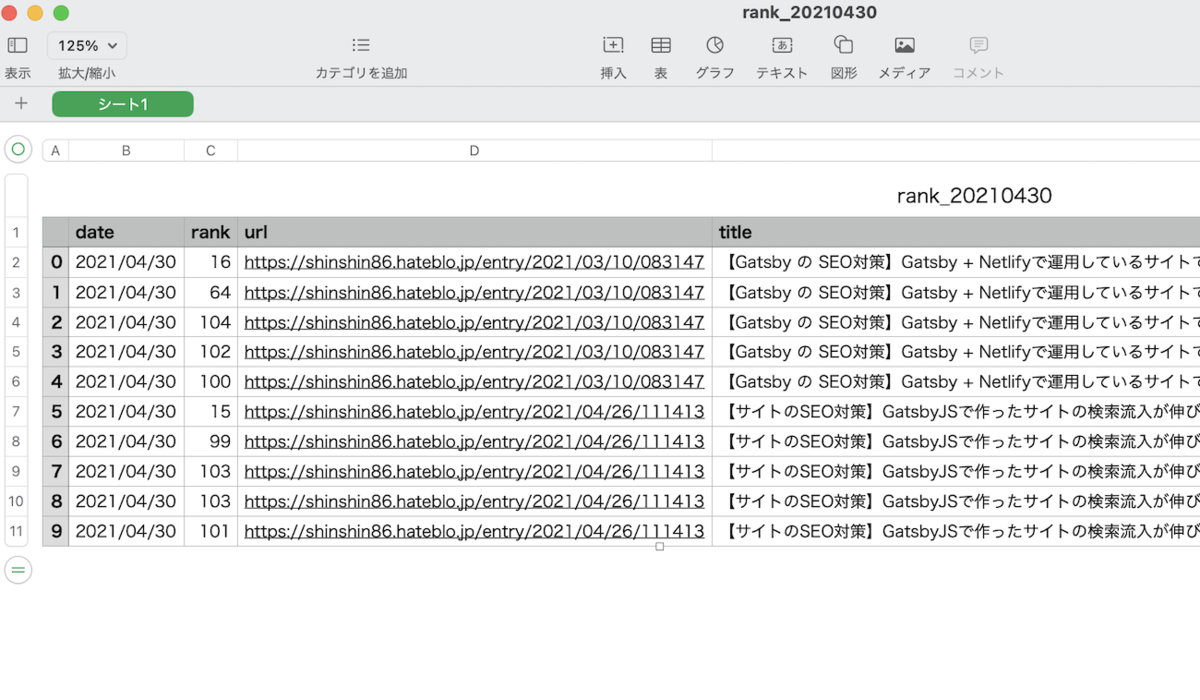
windows環境ならExcelとかで同じように開けるのかと思います。
(記憶が曖昧なので間違っていたらすみません)
ツールの紹介は以上です
このような感じで1日1回実行しながら、指定したキーワードでの検索順位がチェックできます。
先ほども書きましたが実行完了までは時間がかかるので、別の作業の裏で動かしておくような形が良いかもしれません。